
This article is accompanied by a sample workflow which can be deployed from the files in this folder. For help deploying these files, check out our support article on deploying form definitions and server datasets.
Not every member of a survey sample will be a willing respondent. One common compensation mechanism is to "oversample", interviewing more respondents than you need to, in case too many of them do not agree to participate. Alternatively, you can replace them with another respondent. In this article, we will go over how to replace a respondent when using case management. Read on for a full description, but the best way to learn how the system works is to upload it to your own server, and observe how the form publishing works for yourself.
Note: The sample form allows you to select the case ID in a select_one field called "case_id" for the ID of the respondent instead of "caseid", so you can try out this form setup without having to interfere with your current cases dataset. In your actual setup, refer to the field "caseid" instead of "case_id". However, if you open the form from a case, it will use the ID of that case. To learn how to use an alternate dataset ID for case management so you can have multiple cases datasets, check out our documentation on case management, section Different case lists for different teams (they can be used on single-team servers as well). To learn how to set a web form's "caseid" value using unique links, check out our guide to unique links for web forms.
| You may find this approach useful in the context of computer-assisted telephone interviewing (CATI) or non-CATI case management. |
Prerequisites
You should have a decent understanding of case management, pulling pre-loaded data into a form, and publishing form data into a dataset. If you are unfamiliar with these topics, check out these resources:
Case management
Pre-loaded data
Publishing data into a dataset
If you have questions about these features, paid users can reach out to SurveyCTO support, and all users can post their questions to the community forums.
Summary
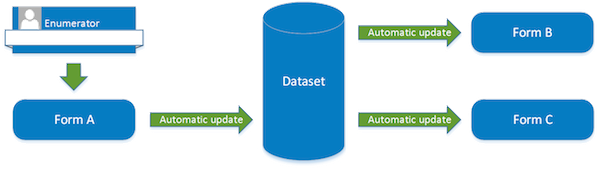
In this workflow, the form pulls information about a respondent from the cases dataset. If the respondent declines to take part in the survey (or should be replaced for some other reason), the following occurs:
- Information about a new respondent is pulled from the "replacement respondents" server dataset.
- Once the form is submitted, the case in the cases dataset is updated with information about the new respondent.
- Optional: Depending on the setup, information about the former respondent is published to the "removed respondents" dataset, and the "replacement respondents" dataset is updated to indicate that the respondent has been added to the cases dataset.
Download copies of all files required to deploy this workflow from this folder.
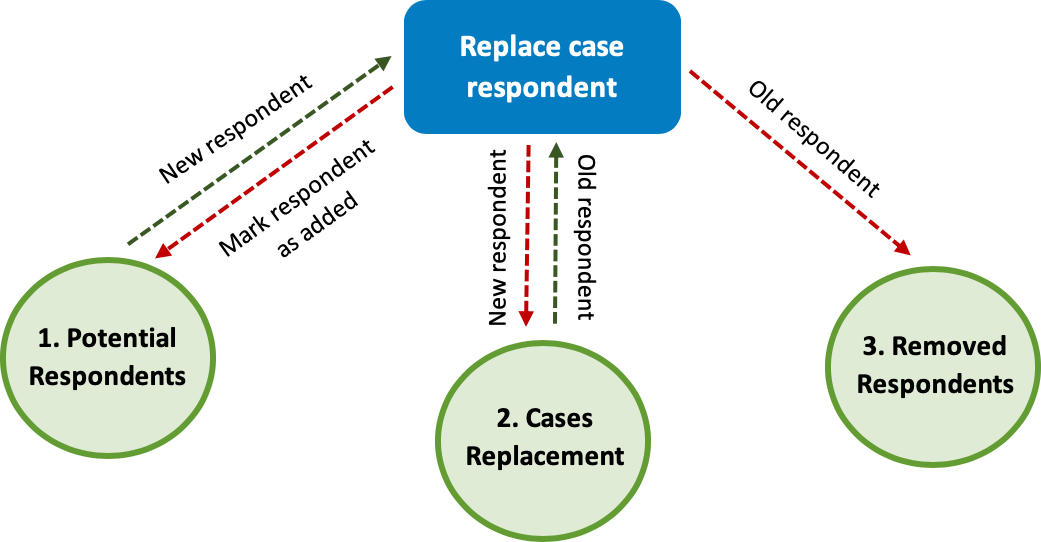
Server datasets
This setup includes three server datasets, one of which is optional.
Replacement respondents
Check out the replacement_respondents.csv file in the resource folder to review the dataset data.
In this dataset, you will store your list of potential replacement respondents. It will contain all information about the replacement respondents that will be needed by the form. In this simplified dataset, it only contains the respondent's name and phone number, but you can also include other phone numbers, their address, preferred name, and any other information you may want to include. This way, when it is time to replace a respondent, you have all of the information you need. Each replacement respondent should also have a unique identifier.
This dataset also has two additional columns: 'possible_caseid' and 'added_to_case'.
'possible_caseid'
If certain respondents should only be added to certain cases, 'possible_caseid' will make sure respondents are not added to the wrong case. In the sample dataset, Adnan, Bhavna, Charles, and Diana should only be replacements for case 1; Evelyn, Francine, Gregory, and Henry should only be replacements for case 2; and so on. You'll also notice that the unique identifier for each respondent, 'resp_key', is a concatenation of the possible case ID and the replacement respondent's individual ID (e.g. the first four respondents' 'resp_key' values all start with _1 since they are all replacements for case ID 1).
|
||||||||
| The respondent named Javed is a possible replacement for the case with ID 3, and he is candidate 2 for case 3 (so the first replacement after the main respondent, Igor). |
This can be helpful for forms with many enumerators. If there was just one long list of replacement respondents, and enumerators are completing forms at the same time, they could end up overlapping and adding the same new respondent to multiple cases. If each case has its own list of replacement respondents, it ensures that enumerators do not make duplicate replacements.
'added_to_case'
The 'added_to_case' column marks the replacement respondent as having already been added to the cases dataset if there is a 1 in that column. This can be a great way for survey administrators to quickly know how many replacements have been required so far.

If there will be at least five minutes between submitting a form instance and downloading the new dataset data from the server), this can also be used to find which replacement respondent should be the next respondent for a case. You can set up the form to cycle through the list until it reaches a replacement respondent that does not have 1 for its 'added_to_case' value. Keep in mind that it can take up to five minutes for a dataset to be updated with submitted data, so this is for workflows where enumerators can wait about five minutes before starting the next case; otherwise, they may accidentally pull a replacement respondent that had already been added to the main dataset.
This column is also used by the "Manually reassign respondent" form to determine which respondents have not yet been added. You will learn more in Reassigning a respondent below.
If you decide you don't need this column at all, you can remove it from the CSV file. You can even just attach the file to your form as a CSV pre-load file instead of a server dataset, since without the 'added_to_case' column, nothing will be published to the dataset.
Current respondents
Check out the cases_replacement.csv file in the resource folder to review the dataset data.
This is the most important server dataset, since it will store the current list of respondents that should be contacted. Simply put, when the enumerator indicates in the form (which we'll get to later) that the respondent for a case will not participate in the survey, then their information will be replaced by information about another respondent. The 'id' and 'formids' values will not change, since these will be the same for all respondents for that case. In the sample setup, the 'label' will not change, but you can absolutely set up form publishing so the 'label' is also updated as the respondent is replaced.
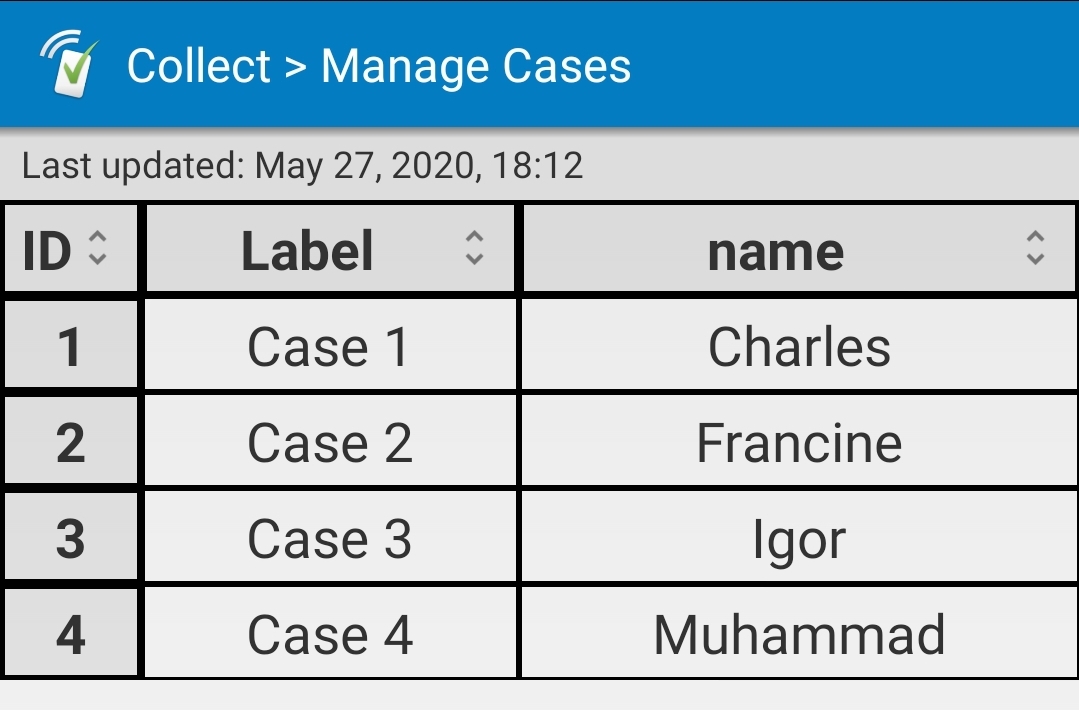
The important column is the 'resp_id' (respondent ID) column. This will store the ID of the respondent in relation to the case ID. This will be used to determine which replacement respondent should replace the current respondent. For example, in case 3, the respondent is Igor, who has a 'resp_id' value of 1. If Igor cannot or will not participate in the survey, the workflow will move on to respondent 2, Javed, who will replace Igor in the cases dataset. If it turns out that Javed cannot participate either, then it moves on to respondent 3, then respondent 4.
| A form can only update one row per server dataset for each submission, but it can update multiple datasets during each submission. This is why in this workflow, we replace a case, as opposed to closing a case and creating a new case at the same time (which isn't possible). In this sample setup, the form updates three server datasets at once, updating one row in each dataset. |
The form also includes columns for the respondent's 'name' and 'best_phone' (best phone number to call). Just like the "replacement respondents" dataset, you can have as many or few of these types of columns as you need.
Removed respondents (optional)
Check out the removed_respondents.csv file in the resource folder to review the dataset data.
When a respondent is removed from the cases dataset, you may still want to keep track of which respondents have been removed from it. In this system, when a respondent is to be replaced, they are added to the "removed respondents" dataset.
Some surveys won't need to keep track of this (and respondent information will still be saved in the form data, and it will remain in the "replacement respondents" dataset), so you do not have to use this dataset in your survey. You can simply not upload it to your server, and all other data retrieval and publishing will continue to work well.
Form definition
Check out the form definition spreadsheet in the resource folder to review the field setup.
The form definition uses its "name" and "phone_number" fields to pull information about the respondent assigned to the case. But, if the field "consent" has a value of 0 (meaning consent was denied), the fields in the group "new_respondent_info" become relevant. This means it pulls the current respondent ID ("current_resp_id"), uses it to calculate the new respondent ID ("new_resp_id"), concatenates that with the case ID to create the respondent key ("new_resp_key"), and then uses that to pull the new respondent information ("new_name" and "new_best_phone"). When the form is submitted, the new respondent information is published to the cases dataset, using the case ID (here "case_id", but it will usually be "caseid") as the unique identifier) to identify which case it should publish the data to. If there is a "removed_respondents" server dataset, then the old respondent information is published there.
You'll also notice a calculate field called "replacing", which stores the static value 1. This is added so that the "removed_respondents" server dataset only updates when "replacing" is 1, which would be when the group "new_respondent_info" is relevant, which is when "consent" is 0. This way, the "removed" dataset is only updated when a respondent is actually being replaced. If you are not using the "removed" dataset, then this field is not necessary.

Reassigning a respondent
Sometimes, an enumerator may go through every respondent on their list. This will make several of the columns in the case row blank, since there is no longer a respondent assigned to that case. However, if another case has been completed, you can reassign replacement respondents to a different case. If you need to reassign a respondent after a case has already run out of respondents, you can use this form definition, which will perform all of the updating and publishing for you. It is recommended that only supervisors should be allowed to complete this form.
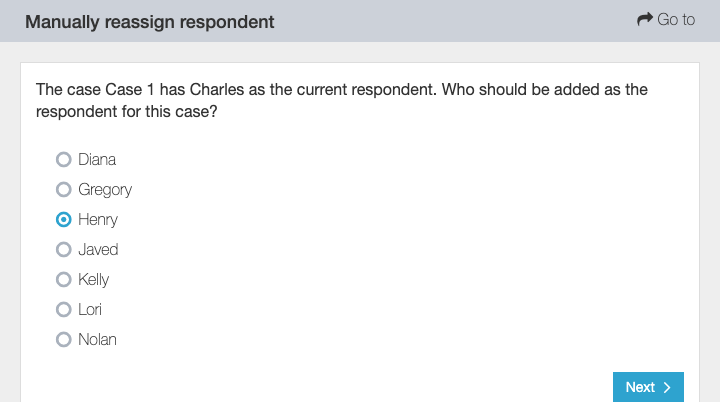
You can also manually reassign respondents proactively by changing the 'resp_key' and 'possible_caseid' values of a respondent. For example, if you see that case 2 is about to run out of respondents, you can go to the "replacement respondents" server dataset on the Design tab of the server console, click on Edit, find another respondent that has not yet been called, and change that replacement respondent's 'resp_key' to 2_5 (since they will be the fifth respondent called for case 2), and the 'possible_caseid' value to 2. That way, if the first four respondents decline taking part in the survey, a fifth will be ready in the list.

If you prefer, you can also modify the data on your computer desktop. Download the server dataset data, modify the CSV file on your computer, and then merge that CSV file into the server dataset. (For assistance with downloading and uploading dataset data, check out our support article on working between servers, section 2.2, and section 2.4 steps 7-10).
When manually reassigning a respondent, it is recommended that you select a replacement respondent at the end of the list. That way, there will not be any gaps. For example, in the replacement respondents list, if Nolan is reassigned to case 1, but then Muhammad says he will not participate in the survey, then respondent 2 of case 4 will be empty, so no replacement will be added to the cases dataset. If instead, Patrick were reassigned to case 1, and Muhammad declines being part of the survey, then Patrick's information will be ready to be added as the replacement respondent.
Further reading
The need to replace case respondents usually occurs during computer-assisted telephone interviewing (CATI). To learn more, check out our CATI starter kit.
This setup assumes the survey is using case management, but you can also have enumerators select the case from within the form. To learn more, check out our support article on how to use the CATI starter kit without case management.
Forms like this are sometimes completed with web forms. To learn more about different web form features, check out our web forms resource catalog.
0 Comments