
This article is accompanied by the sample data collection workflow in this folder. First deploy the two form definitions onto your server, then the 3 dataset definitions, then upload the CSV files to their respective datasets. For help deploying this workflow, read this file.
Important note: Given that this workflow works around usernames, the sample files will only work properly on your server once you edit both the "cases.csv" and "users.csv" files with existing users on your server.
Introduction
Research in multilingual contexts is very common. Some studies cover more than one country, and others involve interviews in countries where many languages are spoken. At the same time, not all enumerators are fluent in all of those languages, although they may speak some of them. Without knowing the language spoken by the respondent beforehand, it’s impossible to allocate the respondents to the enumerators that speak the same language. To help you with this issue, we developed a system that re-assigns cases to different users whenever the respondent doesn’t speak the same language as the enumerator.
The sample workflow is based on the advanced computer-assisted telephone interviewing (CATI) sample form, but you can use this approach in any context. Below, we will go through the specific modifications you should make to your workflow in order to accomplish this goal.
Form design
There are two features to add to the advanced CATI sample: 1) Register or update the language spoken by the respondent, and 2) Match the case with a user that speaks the same language.
1. Registering the language spoken by the respondent
A call for a phone interview can either be answered by a respondent or by someone else, and you might be able to confirm the language spoken by the respondent in both of these cases. Still, there are 3 different scenarios to take into account:
- If the call was answered and the enumerator does not speak the same language, they won’t be able to communicate. For this reason, a new choice was added to the choice list of the “response” field (row 83 of the sample form). In case they don’t speak the same language, the enumerator should select “Respondent does not understand. Case requires language matching.” In this case, the enumerator may not be able to tell whether they are speaking with the respondent of the study or someone else.
- If the call was answered by the respondent and the enumerator is able to communicate with them, the first question of the survey will be “What is your home language, or preferred language to speak?” (see the "main_language" field). If the response is a language spoken by the enumerator (see the “user_language” field”), the form will allow them to move forward. Otherwise, the enumerator will be led to the language matching step. While they might be able to communicate to some extent, fluency should be required for the main survey questions, so the case should be re-assigned based on the respondent's preferred language. If their preferred language matches the enumerator language, it is still helpful to register the respondent’s language for any later stage of your project.
- If the call was answered by a family member, friend or neighbor, and the enumerator is able to communicate with them, they might know the respondent well enough to provide you with their dominant language. In this case, the language will be requested right after requesting the best contact number.
To make sure that we are covering all scenarios, there are the options “Can’t identify the language (pick if you don't understand the person speaking)” and “Doesn't speak any of the languages above”. If either of these is selected, then the case will end up under review (to learn more about this CATI form design strategy, take a look at part 3 of the CATI starter kit, under section 4. Cases to be reviewed).
What happens in subsequent calls?
While this workflow will register and publish the primary language of the case into the cases dataset, this primary language might not be the correct one:
- In scenario 1, we are registering a language without knowing whether it’s the respondent on the other side, and sometimes not even being able to identify the language .
- In scenario 3, we are registering a language provided by someone related to the respondent. While it might be correct, we can only confirm and be certain after speaking directly to the respondent.
Given the above, the question “What is your home language, or preferred language to speak?” will be relevant until the consent is given by the respondent. At this point, we’ve had direct contact with the respondent and have asked them their preferred language directly.
2. Reassigning the case to a user that speaks the same language
At this point, we will require a list of all users (enumerators) and the languages they speak and understand. For that, we will have an additional server dataset with the dataset ID “users” that will contain this information. But we should also take into consideration the number of cases assigned to each user before reassigning a case. Ideally, all users should have a balanced number of assigned cases. Particularly when reassigning respondents, we want to avoid overworking some enumerators while others don’t have enough interviews to do. Regretfully, it’s not possible to keep track of the total number of cases assigned to each user. Whenever a case is reassigned, the update of the total number of cases is twofold:
- The current user will have one less case, and
- The new user will have one more case.
However, the publishing configuration will only enable us to update either 1) or 2), not both. This is because data publishing updates a single row in a server dataset, and 1) and 2) are on two different rows.
In this sample form, we’re keeping track of the total number of cases reassigned to each user, i.e., point 2), so the user with fewer cases reassigned to them should be the one selected whenever language matching is required.
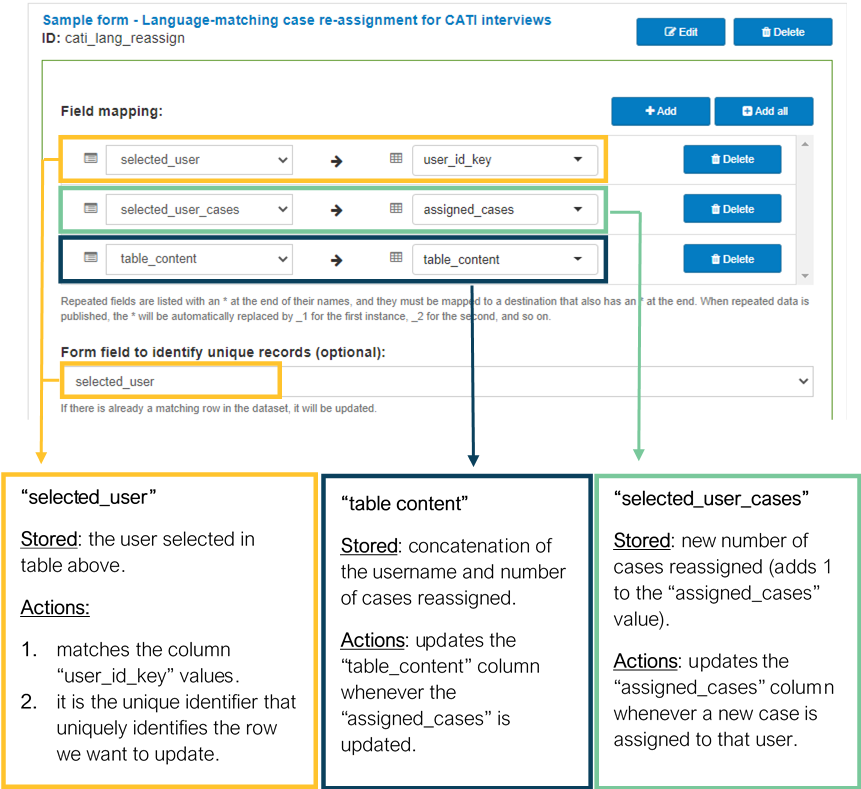
Using our table-list field plug-in, all users that speak the same language as the respondent, stored in the previous step, will be displayed in a table with their names and number of cases reassigned. Here, the enumerator should select the user with the fewest cases reassigned to them:

Once the form is submitted and sent to the server, the users column of the cases dataset will be updated by the field “pub_to_users” to include the newly selected user.
New server dataset "users"
The sample dataset data can be found here.
This workflow was already dependent on one server dataset before (with and without case management) that includes information about each respondent and each contact attempt. In order to reassign users to cases depending on their own characteristics (language spoken and number of reassigned cases), a new, additional server dataset is required.
This new server dataset has the following attributes:
- table_content contains the content that will be shown for each row of the table displayed in the field “selected_user”, according to the table-list field plug-in requirements.
- user contains the names of the enumerators that will be displayed.
- user_id_key contains the enumerators’ SurveyCTO usernames.
- languages contains all languages spoken by each enumerator, separated by commas (e.g. “Language 1,Language 2”). To ensure that the item-at() function works properly in the form design, be careful not to add any space between commas.
- assigned_cases contains the total number of cases reassigned to each user.
This server dataset is the source of data for the language matching group of the survey design, and the assigned_cases column will be updated according to the number of cases reassigned.
| The cases dataset from the advanced CATI sample workflow has also been updated to include an additional column “language” that stores the preferred language of the respondent. |
Adjustment of reassignments
Assuming that enumerators have a roughly equal number of cases assigned, and that the rate of reassignment is similar, this system might work well unmanaged. However we suggest that you keep an eye on it. The "reassigned_cases" field in the "users" server dataset can tell you how the burden of work is shifting due to reassignment. As cases are reassigned, you might want to make some of your own re-assignments.
As per the case management documentation, cases are uniquely assigned to a user when their username appears by itself in the "users" column of a cases dataset (i.e. their username is the only one listed in the "users" column). This can be manually edited on the Design tab if the dataset is under a certain size. If it is not possible to edit online, you can export the cases dataset data, identify the cases you want to reassign, change the "users" values, and upload, merging in those records. In fact, you only need two columns in the uploaded data to re-assign cases: "id" and "users".
Options for augmentation
In the real world, people can speak many languages of varying, but sometimes comparable proficiency. However, in this sample, for simplicity, we cater for only one preferred interview language. This was useful for making the sample form simpler to follow and modify. However, you may wish to capture multiple potential interview languages, which would be possible to do. Try your hand at this, and if you need help, start a support request, or post a question in our community forum.
Do you have thoughts on this support article? We'd love to hear them! Feel free to fill out this feedback form.
0 Comments